Calfa Releases an Open Source OCR Model for Armenian
Optical Character Recognition (OCR) is an essential step in converting documents into usable, editable, and searchable data. This technology is now widely used by the general public, industries, and heritage institutions, such as digital libraries.
For Armenian, there are several available solutions, the most well-known being:
- Tesseract-OCR, an open-source package developed by Google and used as the foundation for most online services. The Armenian model covers a wide range of modern fonts and enables the transcription of clean documents;
- Abbyy, a licensed software that allows individuals to transcribe standard Armenian documents with high recognition rate;
- Calfa OCR, a subscription-based online service that supports all handwritten scripts and heritage printed fonts, regardless of document quality.
For more information on OCR performance for Armenian, click here
| Tesseract | Abbyy | Calfa OCR |
|---|---|---|
| Package | Software | Service |
| Free | Licence | Prepaid offer |
| Print and Handwritten | ||
| Common fonts, clean documents | Common documents | Complex fonts and documents |
What’s new?
We trained a new version of Tesseract’s Armenian model, which we’re releasing as open source. This choice is driven by our desire to support the digitization of Armenian, offering a lightweight and easy-to-implement solution for everyday needs.
➢ About the model and open science
We improved it using data that better represents 20th-century Armenian print production, with a particular focus on damaged documents and old fonts—areas where Tesseract typically struggles. The model supports texts in Classical, Western, and Eastern Armenian. Here are a few recognition examples:
Example 1 : Blurry Armenian newspaper (-20% of mistakes)

| Tesseract default | Tesseract Calfa | |
|---|---|---|
| Character Error Rate (CER) | 28,95 | 8,61 |
| Word Error Rate (WER) | 95,96 | 52,22 |
Example 2 : Noisy Armenian Book from the 20th century (-28% of mistakes)
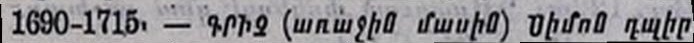
| Tesseract default | Tesseract Calfa | |
|---|---|---|
| Character Error Rate (CER) | 36,64 | 8,11 |
| Word Error Rate (WER) | 101,22 | 44,38 |
Example 3 : Binarized Armenian Book (-8% of mistakes)
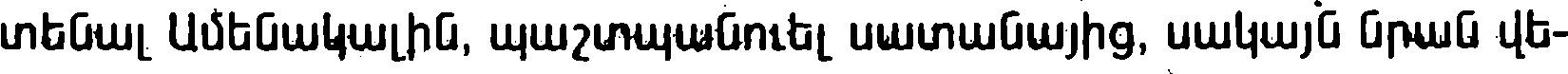
| Tesseract default | Tesseract Calfa | |
|---|---|---|
| Character Error Rate (CER) | 11,75 | 3,99 |
| Word Error Rate (WER) | 50,07 | 21,51 |
Example 4 : Historical Armenian font (-35% of mistakes)

| Tesseract default | Tesseract Calfa | |
|---|---|---|
| Character Error Rate (CER) | 48,93 | 13,47 |
| Word Error Rate (WER) | 134,90 | 67,63 |
✅ What this model does:
- Transcribes old fonts;
- Transcribes damaged documents or scans;
- Supports Classical, Western, and Eastern Armenian.
❌ What this model doesn't do:
- Layout analysis: relies on Tesseract’s default layout analysis capabilities;
- Post-OCR correction
Why and how to use it?
This model can be used locally by installing Tesseract-OCR, or integrated into a service using the pytesseract API. It’s also available through our processing tool at ocr.calfa.fr.
OCR technology is now more accessible than ever, including within generative AI models. This model is extremely lightweight (3 MB), with inference times under one second for standard pages. It offers a fast, efficient, and cost-effective alternative for a wide range of OCR projects.
For more specialized needs, feel free to contact us for a personalized assessment of costs and feasibility.
➢ To know more about Calfa and open science
{kind=link}